- GM, No Fomo
- Posts
- 🗿 All LLMs are converging to the same point
🗿 All LLMs are converging to the same point
How to know what's next for crypto

GM. Just wrapped a 60-page doc, 120-slide RFP that took hundreds of hours to make. It got me thinking.. how far away are we from automating creative services? Will it ever be possible? Should it be possible?
LLMs are designed to automate the binary, the manual. The things that can be replicated over and over. Like when I worked in leveraged loans and had to fax allocated trades to brokers.
But complex creative processes, like how to make a movie, will always require human input – if you want it to be unique. Why? Because to be creative, you have to be different. And all LLMs are converging to be the same.
To stand out in the age of automation is to do the un-automated.
Sure, one-man award-winning movies are possible. AI-generated IP may generate billions.
But a cookie cutter Marvel movie made by robots, if it performs well in the market, is more indicative of poor cultural taste and economic preference than it is an existential threat to the human ability to make superior art in the age of automation.
So here's my ode to human creativity, and why it will always have a place in business and culture (aka i'm not worried about my job security).
Without Further Ado. ☕ *knuckle cracks* ☕ Let’s get into it.
VaultCraft launches V2, TVL skyrockets above $100M

VaultCraft launches V2, partners with Safe, and secures $100M+ in Bitcoin
Matrixport, Asia’s leading crypto providers, commits $100M+ in Bitcoin
OKX Web3 to launch Safe Smart Vaults with $250K+ in rewards
First off. Here's our AI creative tech stack:
To explain how creativity can never be fully automated, let's start with how we're using tech today.
Yes. We use AI for our creative ops. But we’re nowhere close to automating our creativity. We're leaning hard into trimming the fat.
Our high-level AI creative tech stack at Supernova:
Custom model of Perplexity and Claude for research
Custom GPT model for process outlining & text-editing
Midjourney, Luma AI for image + video, storyboarding
Adobe Creative Suite for editing & post-production
Play.ai, Eleven Labs for sound
Topaz for optimization
We use more tools — but this is the bread and butter.
Why don't we use one company for all our AI creative tooling? Because they each have different use cases. There is no super AI app and there never will be.
Even OpenAI can't automate their creative ops
I kind of had an “aha” moment when I spoke with an Executive at buck.co, and she told told me they designed all marketing assets for OpenAI.
Why would one of the world’s leading AI companies spend millions of dollars on an external vendor for creative services?
twitter hype is out of control again.
we are not gonna deploy AGI next month, nor have we built it.
we have some very cool stuff for you but pls chill and cut your expectations 100x!
— Sam Altman (@sama)
8:32 AM • Jan 20, 2025
Because creativity cannot be automated. And if you want to be the best of the best, it never should be. I’m not an engineer so feel free to reply and correct me if I’m wrong.
But this is my understanding for how LLMs work, why they are inherently limited, and why that’s actually a good thing.
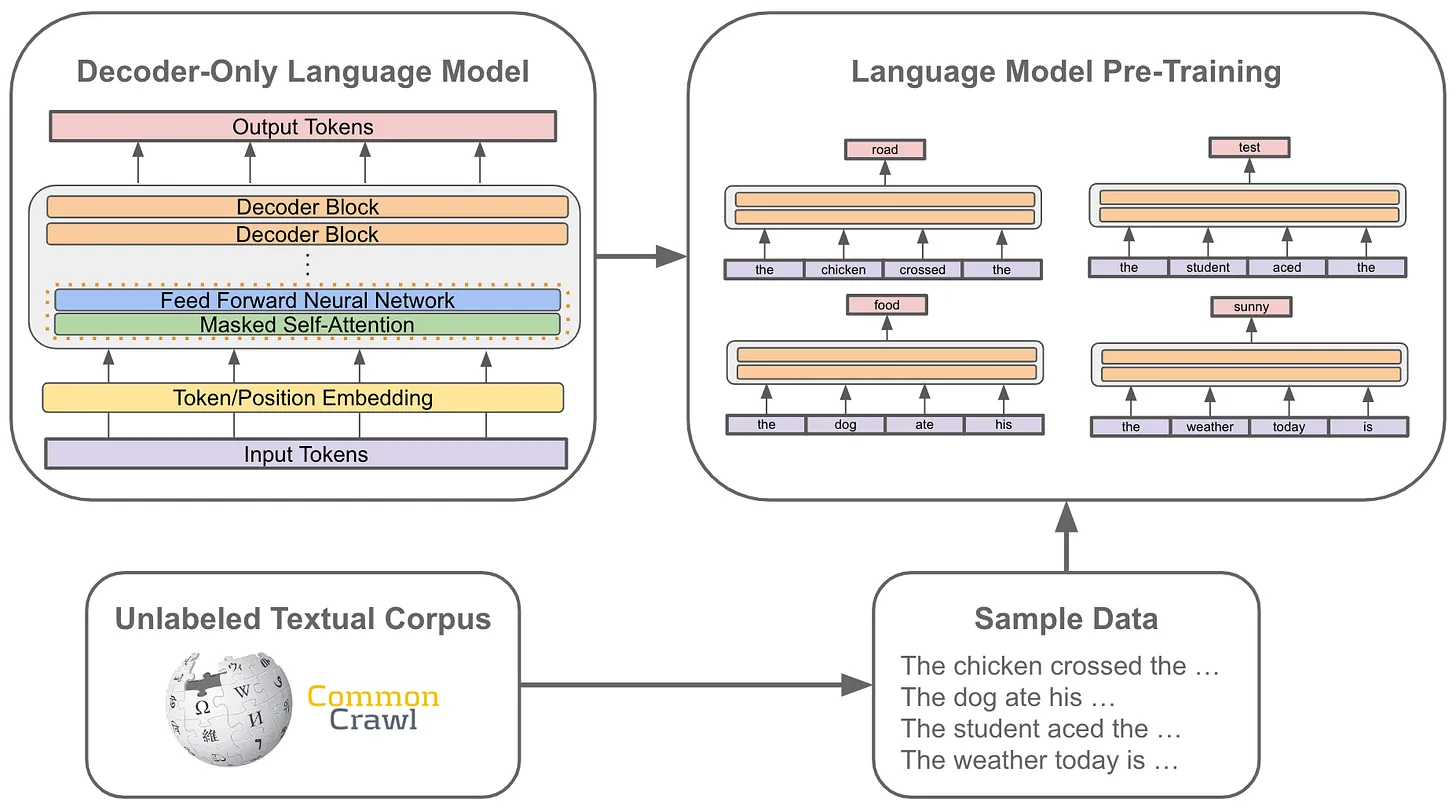
Language models are based on data scraping on the Internet. It’s a battle of who has the best data. And no language model is capable of having all the information. Just like no country is capable of having all the money in the world.
Without absolute totalitarianism or some far-off utopia, it is not feasible. Ok, so each dataset is limited and distinct, right?
Well not exactly.
Because in order to be a LLM, you have to pull from a ton of public data. And many of them used the same web scrapers as pre-training, to the point where it feels like all LLMs are converging to the same point. From this rabbit hole Reddit thread,
“I generated a list of 100 items last night. I used Gemini, GPT4, GPT4o, llama405B, MistralLarge, CommandR an DeepSeek2.5
Outside of deepseek, the first 6 generated almost identical dataset and grouped them almost exactly the same. The yapping was obviously different between the models, but the main data I needed was damn near exactly the same. The order of the data by category was also similar. As I stared at the data, it dawned on me that they are all converging towards toward the same location.
I don't think that location points to ASI. I suppose with them all being trained on almost same data it's to be expected, but it got me thinking.”
One reply pointed out:
“The original LLMs, namely GPT-3.5/4 and llama 1 used web scrapers to scrape a large portion of Internet content, and format it into a dataset. They then used this as pre-training data, which produces a base model, which is effectively a high quality text autocomplete. This base model then undergoes instruct tuning, which teaches it to follow instructions and thereby chat with people. In the case of chatgpt, they taught it to respond in a professional, dry, robotic, corporate manner. They also used RLHF in order to rank its responses, and optimize for human preference. However in the case of llama one, because this was prior to mass usage of synthetic data, it actually had very colorful, realistic, human-like use of language, but terrible intelligence compared to GPT.
After the Llama one leak, the first fine tunes of llama one came out, these were purely research oriented, but the original Alpaca and Vicuna were research showing that training large language models on GPT 3.5 chat logs significantly improved its performance. People begin to collecting GPT chat logs, and turning them into massive data sets, leading to what we know nowadays as synthetic data, in other words, data generated by an llm.
The use of synthetic data is essentially a form of distillation, which means to take a large model, and train a small model on its outputs, to optimize the smallest models intelligence and responses to be as close to the large model as possible.
Meta almost immediately caught on to how effective the usage of synthetic data was, and used it in its training data sets for llama 2, causing intellectual capabilities to skyrocket, but the manner of speech and verbal tics of GPT were now included in the Llama series. After this came Mistral 7b, a small open source model, by a small open source startup, but it showed that even a small model can be significantly better than a large model, if trained properly. Mistral, being a French company with not that many resources, has always relied very heavily on synthetic data.
Mistral 7B kicked off the small model craze, in which experimentation and new techniques for optimization were rampant, and RLHF generally fell out of favor in both the open source company community and the corporate community since it requires human labor, is slow, and is expensive, and therefore can only be done by large corporations, which was a huge problem for the open source community. It was replaced by much newer techniques like DPO (direct preference optimization) and experimental ones like SimPO or KTO.
One of the most common complaints during this era was that every model talked exactly like chatgpt. Meta caught on to this, and when they released llama 3, they used DPO during the training phase, to make the model seem much more friendly and human. This boosted its place on a human preference leaderboard, lymsys, and caught on very quickly. Other models followed suit, with Claude 3.5 also opting for similar friendly speech, and Gemma 2 doing the same. Nowadays, that is the standard.
I'm no fine tuner, so my understanding is limited, but modern synthetic data collection generally works by creating a data set of questions, figuring out what is considered the "best" model at the time, and then making tons of API calls in parallel, and adding the llms response to the data set. As of right now, that would be Claude 3.5 sonnet. However, some people prefer to open a run pod instance or host locally, in which case they get the best local model they can get their hands on, which is either Mistral Large 123b, or llama 3.1 405b, and have it generate the answers to the data set.
I know for a fact that synthetic data is heavily used during instruct tuning, but as for how it figures into pre-training, I'm not quite sure, you may want to read a paper about that”.
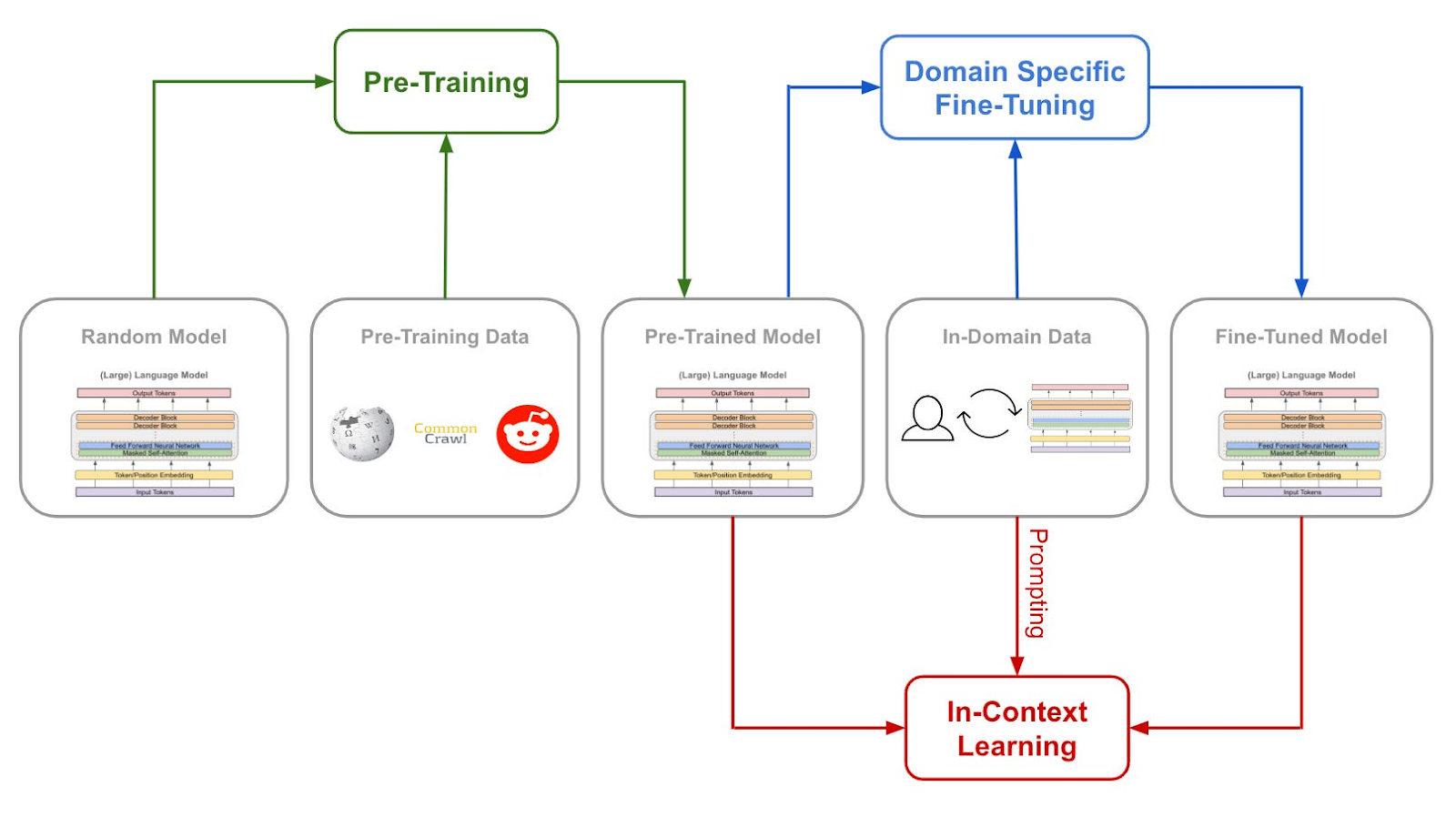
These charts are from a great read by Cameron R. Wolfe (spelt his last name wrong), who dives deeper into how language models are trained.
The TLDR: unless one mega model trained its data on all human activity ever, and had all humans as users for in-context training to enhance it even further, no AGI can dominate creative services on its own.
And even so, how could this superhuman create ideas without the influence of historical data? Humans would still be capable of creating net-new ideas. Essentially, they would achieve Inception, and if they did, this being would truly be the manifestation of God. Maybe that’s the Second Coming of Jesus we’ve been waiting for.
I’m sure there are a million holes in my reasoning here. But a good thought starter for where we’re headed nonetheless. Because I think we will find out the answer sooner than later, as technology accelerates, manual tasks diminish, and humans are left to uncover the darkest corners of the Universe.
What we’re reading
Your daily AI dose
Mindstream is your one-stop shop for all things AI.
How good are we? Well, we become only the second ever newsletter (after the Hustle) to be acquired by HubSpot. Our small team of writers works hard to put out the most enjoyable and informative newsletter on AI around.
It’s completely free, and you’ll get a bunch of free AI resources when you subscribe.
Reach Over 100 Million Humans
This is NOFOMO, the newsletter keeping you up-to-date on all things emerging tech.
No Fomo is part of Supernova’s media conglomerate - a media network reaching 100 million humans and over 10 billion impressions/month across socials, gaming, newsletters, and podcasts.
DISCLAIMER: None of this is financial advice. This newsletter is strictly educational and is not investment advice or a solicitation to buy or sell assets or make financial decisions. Please be careful and do your own research.
Reply